使用 LLM embeddings 进行数据存储和检索的新姿势

大语言模型可以将文字转化为 embeddings, embeddings 是一个向量(浮点数) 数组。把向量数组存到数据库,然后我们通过搜索最接近的向量就可以得到搜索结果了。本文试验了这一方式。
概述
本文的过程大概如下:
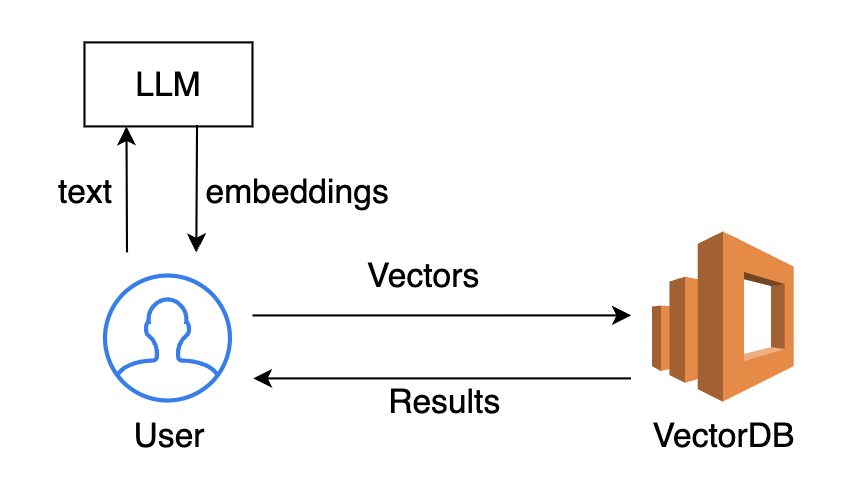
本文将代码片段分解在了各小节,你如果要运行此文章的代码,可能需要一点 nodejs 的知识。你也可以直接转跳到最后一小节看效果。
调用本文章的代码需要设置如下这些环境变量:
- OPENAI_API_KEY
- AWS_ACCESS_KEY_ID
- AWS_SECRET_ACCESS_KEY
向量计算
首先你要有一个大语言模型,需要将文本计算出向量,你可以部署一个私有的,也可以调用 API。
下面的函数 使用了 OpenAI 的 API 来获取向量值。
const { OpenAIEmbeddings } = require("langchain/embeddings/openai");
const embeddings = new OpenAIEmbeddings({ temperature: 0.9 });
const toVec = async text => {
return await embeddings.embedQuery(text);
}
向量数据库
我们需要一个数据库能支持向量的存储和查询,可以使用专门的向量数据库,也可以使用 OpenSearch(Elastic Search),他的 knn 插件即可用来干这个。
我们先去 AWS 开通一个 OpenSearch,验证方式先使用 IAM User,稍后我们通过该 User 的 AKSK 来访问 OpenSearch。
请注意:需要使用 OpenSearch 而不是 OpenSearch Serverless。(OpenSearch Serverless 还不支持 knn 插件,2023-4-24)
建索引
首先创建索引,如下面的代码:
const { defaultProvider } = require('@aws-sdk/credential-provider-node'); // V3 SDK.
const { Client } = require('@opensearch-project/opensearch');
const { AwsSigv4Signer } = require('@opensearch-project/opensearch/aws');
const client = new Client({
...AwsSigv4Signer({
region: 'us-east-1',
service: 'es',
getCredentials: () => {
const credentialsProvider = defaultProvider();
return credentialsProvider();
},
}),
node: "https://xxxxxx.us-east-1.es.amazonaws.com"
});
var index_name = "doc_embeddings";
const createIndex: async _ => {
var response = await client.indices.create({
index: index_name,
body: {
"settings": {
"index.knn": true
},
"mappings": {
"properties": {
"content_vec": {
"type": "knn_vector",
"dimension": 1536,
"method": {
"name": "hnsw",
"space_type": "l2",
"engine": "nmslib",
"parameters": {
"ef_construction": 128,
"m": 24
}
}
}
}
}
},
});
console.log("Creating index:");
console.log(response.body);
},
插入数据
参考下面的方法:
const updateData = async (id, data) => {
var response = await client.index({
id,
index: index_name,
body: data,
refresh: false,
});
console.log("Adding document:");
console.log(response.body);
},
现在我想通过 url 直接让 OpenAI 对网址进行概括,并计算出向量值,存入数据库中。
这个是我要抓的 Url:
const datasets = [
"https://www.pinecone.io/learn/vector-database/",
"https://www.infoq.com/news/2023/04/logic-apps-new-data-mapper/",
"https://aws.amazon.com/cn/blogs/china/large-scale-dynamodb-table-data-cross-account-migration-guide/",
"https://aws.amazon.com/blogs/startups/8-highlights-from-aws-startup-day-miami-you-want-to-experience/",
"https://www.baeldung.com/java-serialization",
"https://www.baeldung.com/mockito-lazy-verification"
];
调用 OpenAI,让他去帮我们总结文章内容。
const briefUrl = async url => {
return await model.call(`Summarize this url in English: ${url}`);
};
连起来调用:
const updateDataByUrl = async (id, url) =>{
const brief = await briefUrl(url);
const content_vec = await toVec(brief);
await updateData(id, {
id,
content_vec,
url,
brief
})
};
for (const index in datasets){
updateDataByUrl(
index,
datasets[index]
).catch(console.log);
}
查询
到此为止,我们已经灌进去了几篇文章,这几篇文章大概是:
0: 介绍向量数据库的
1: 微软 VS 的一个 Data Mapper 新功能
2: AWS DynamoDB 的迁移
3: AWS Miami 创业日的亮点
4: Java 序列化的方法
5: Mockito 的懒验证方式
下面是查询函数,返回了 2 条相关结果,最接近的数据排在了最前面:
// 通过向量查询
const searchVec = async vq =>{
var query = {
size: 2,
query: {
knn: {
content_vec: {
"vector": vq,
"k": 2
}
}
},
};
var response = await client.search({
index: index_name,
body: query,
});
return response.body.hits;
};
// 封装成关键字,这里又问了 OpenAI 一下。
const search = async q=>{
const qVec = await toVec(q);
return await searchVec(qVec);
};
调用:
search("微软").then(res => {
res.hits.map(rec=>{
console.log({
_id: rec._id,
_score: rec._score,
url: rec._source.url,
brief: rec._source.brief
})
})
}).catch(console.log);
我存入的向量值都是通过英文计算出来的,现在我们就可以按照语义理解来查询了。
下面列举了查询的词语和和第一条结果。结果中的 brief 是使用 AI 帮忙总结的文章内容,并且 embeddings 值也是通过他计算出来的。
“微软”:
{
_id: '1',
_score: 0.6547316,
url: 'https://www.infoq.com/news/2023/04/logic-apps-new-data-mapper/',
brief: '\n' +
'\n' +
"This article discusses Microsoft's Azure Logic Apps Data Mapper, a new feature that enables developers to easily map data between different sources and applications. The article outlines the various benefits of this tool, such as enabling better data integration and making complex data migrations easier. It also explains how the tool can help organizations migrate to the cloud more quickly and easily."
}
“亚马逊”
{
_id: '3',
_score: 0.6621346,
url: 'https://aws.amazon.com/blogs/startups/8-highlights-from-aws-startup-day-miami-you-want-to-experience/',
brief: '\n' +
'\n' +
'This article summarizes the highlights from AWS Startup Day in Miami. It includes topics such as inspiring stories from entrepreneurs, tips on how to succeed in the startup world, and additional resources for those in the tech industry.'
}
“データベース” - 数据库的日语
{
_id: '0',
_score: 0.6666581,
url: 'https://www.pinecone.io/learn/vector-database/',
brief: '\n' +
'\n' +
'This article provides an introduction to vector databases, which are databases that store and process data in vector, rather than the traditional tabular, form. It outlines the advantages of using vector databases, such as faster query performance and more powerful analysis capabilities, and describes the components of a vector database and how they function.'
}
“如何迁移亚马逊云的数据”
{
_id: '2',
_score: 0.69728285,
url: 'https://aws.amazon.com/cn/blogs/china/large-scale-dynamodb-table-data-cross-account-migration-guide/',
brief: '\n' +
'\n' +
'This website provides a guide for those wishing to migrate large amounts of data from one DynamoDB table to another, between different AWS accounts. It covers topics such as what data can be migrated, best practices, and step-by-step instructions.'
}
我还测试了几个,比如 “I have no time” 查到了 懒加载,”怎么做生意” 查询到了 aws 创业日。
从整个逻辑可以看到 LLM 语言模型的能力越强,你的数据库系统的语言理解能力越强,然后就是要看数据库向量检索的能力了,现在市面上已经有很多的向量数据库了。
在 AIGC 和大模型的当下,还有很多事情可以做!大家加油!
参考:
https://opensearch.org/docs/latest/search-plugins/knn/knn-index/